Reward Hacking 101
June 6, 2025
At OpenPipe, we use Reinforcement Learning (RL) to train highly reliable agents. In this post, I’ll share everything we’ve learned about reward hacking, and how to deal with it while training models with RL.
Reward hacking is old as the hills
“When a measure becomes a target, it ceases to be a good measure.” - Charles Goodhart
“What gets measured gets managed even when it’s pointless to measure and manage it, and even if it harms the purpose of the organisation to do so.” - Simon Caulkin (summarizing V. F. Ridgway)
“You are technically correct… the best kind of correct.” - Futurama
Reward hacking isn’t some new thing that appeared with the advent of reinforcement learning. Similar failure modes appear in highly diverse contexts. Let’s discuss a few.
- Large organizations are often shockingly inefficient because of imperfect incentives. The CEO wants everyone to singularly focus on the org’s success, but each SVP is actually trying to look good for the CEO (or other orgs that may poach them), each VP wants to look good for their SVP, and so on. This is known as the principal-agent problem, and it’s devilishly difficult to solve. We still haven’t cracked it despite centuries of exploration in organizational design, and we suspect we never will.
- Governments often create imperfect incentives that can be gamed. In a famous incident, the British colonial government in India, while trying to control the population of deadly cobras, paid a bounty for each cobra killed. This led to breeders intentionally breeding cobras for the bounty, eventually increasing the overall cobra population.
- Exploiting imperfect incentives isn’t even unique to humans! Flowers produce nectar to encourage birds and insects to help them pollinate. But the carpenter bee robs nectar by cutting a small hole in the base of a flower and sipping the nectar through it, avoiding pollination and bypassing the purpose of the nectar incentive.

A carpenter bee reward hacks a flower by drinking its nectar while skipping pollination.
Next, let’s talk about how these failure modes play out in reinforcement learning.
Reward Hacking in RL
Reinforcement learning (RL) is the art of teaching a model to achieve a goal by responding to incentives. As you’d expect, these incentives don’t always perfectly match the system’s goals. When that happens, the model can learn behavior that is technically incentivized (or “rewarded”) while still not doing what we really want. In RL we call this reward hacking.
In 2016 OpenAI published an iconic example of this. They showed how a model trained to maximize its in-game score in a game called CoastRunners learned never to finish the race. In their words:
The goal of the game—as understood by most humans—is to finish the boat race quickly and (preferably) ahead of other players. […] The RL agent finds an isolated lagoon where it can turn in a large circle and repeatedly knock over three targets, timing its movement so as to always knock over the targets just as they repopulate. Despite repeatedly catching on fire, crashing into other boats, and going the wrong way on the track, our agent manages to achieve a higher score using this strategy than is possible by completing the course in the normal way.
Frontier models aren’t immune
As modern reasoning models are increasingly trained with RL, they show signs of reward hacking as well. We see clear evidence of this even at the frontier. Prominent recent examples include:
- When faced with a difficult coding problem, Sonnet 3.7 will sometimes just edit the test cases to pass, instead of implementing the desired functionality. It was clearly trained with a reward function that checked whether test cases pass, which it learned to hack. The Claude 4 model card acknowledges this (and claims Claude 4 does better).
- Gemini 2.5 Pro will add copious try/catch statements to all the code it writes, and silently swallows even important errors if it can. It was likely penalized heavily in training to avoid throwing errors at any cost!
- An April 2025 update of GPT-4o in ChatGPT was extremely sycophantic, agreeing with users in almost every circumstance, even encouraging schizophrenic users to stop taking their medicine. It was likely trained against a reward signal of user approval, and a substantial fraction of testers must have appreciated this behavior. However, it’s not what OpenAI intended, and they quickly rolled back the update and published a postmortem on the update.
Reward hacking: how to fix it
At OpenPipe we’ve trained hundreds of models with RL across dozens of tasks. The bad news is that for every single task we’ve trained on that doesn’t have a 100% verifiable reward, we’ve seen the model learn to reward hack, given enough iterations. The good news is that reward hacking is actually pretty easy to detect and fix, at least for small models and narrow tasks!
We’ll give two representative examples below, and highlight how we addressed each of them.
The Case of the Phantom Layoffs
A few months ago we trained a model to generate optimized HN titles. The high level steps were:
- Train a reward model to predict the number of upvotes a story would receive, based on its title and contents.
- Train an LLM to take a story and generate the title most likely to receive upvotes, using the score predicted by the model trained in (1) as the reward.
This is what the reward graph looks like:
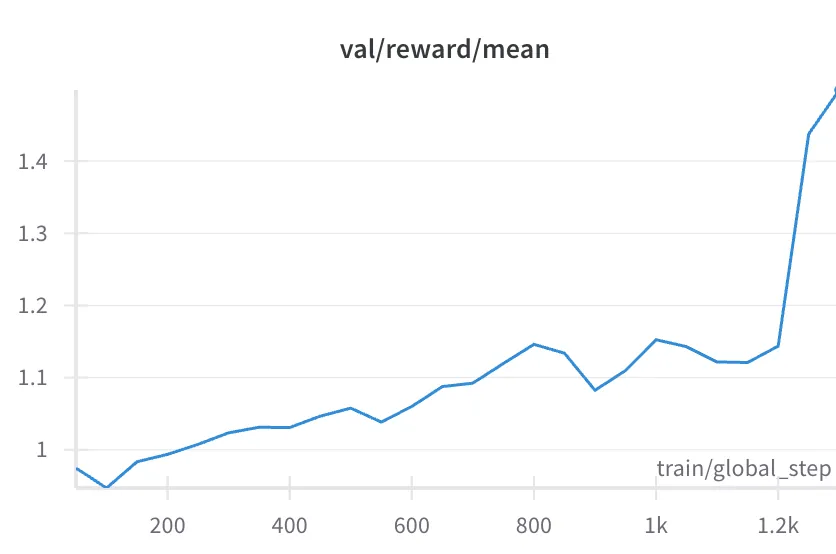
As you can see, there’s a steady increase in the reward signal over the first 1000 steps. And then, around step 1200, a sudden spike! Quick quiz: is this more likely good or bad? This is an article about reward hacking, so you probably guessed “bad”—if so, you’re right.
So, what happened? To find out, we need to look at our traces. There are lots of tools that can do this—our open-source RL library, ART, automatically saves YAML logs of all “rollouts” (agent runs) that you can view, and we often also use third-party observability tools like W&B Weave or Langfuse to view agent runs and see what’s actually happening.
In this case, by viewing the runs, we saw that for the first 1000 steps or so the model is learning useful tricks—like the fact that HN articles with lowercase titles generally do a bit better. But it also learns some less-useful tricks, or proto-reward-hacks, like the fact that titles with exaggerated claims seem to do better, even if they aren’t fully supported by the article.
And finally, an enormous jump in reward comes because it learns the ultimate hack. In fact, it discovers what might be the platonic ideal HN title for maximizing upvotes. At around step 1200, the model learns to completely ignore the article body, and give every single article an identical title: “Google lays off 80% of workforce (2023)”. We have to hand it to the LLM here—we agree that an article with that title would likely be highly upvoted!
Luckily, once we’d identified the problem, the fix is very simple. We simply added an additional LLM-as-judge check to every candidate title ensuring it is fully supported by the article, and giving it a score of 0 if the check failed. With that minor change, the model is no longer rewarded for its hack, and began producing more appropriate titles.
The Case of the Phony Connections
NYT Connections is a popular daily puzzle. You’re given 16 words, and the goal is to divide them into 4 groups of 4 based on an (often subtle) connecting theme. This is a challenging task for small language models, since it requires significant world knowledge and lateral thinking. An engineer at OpenPipe decided to try it anyway though.
At first, the model didn’t learn much. But around step 42, it jumped from ~30% accuracy (random guessing) to almost 100%!
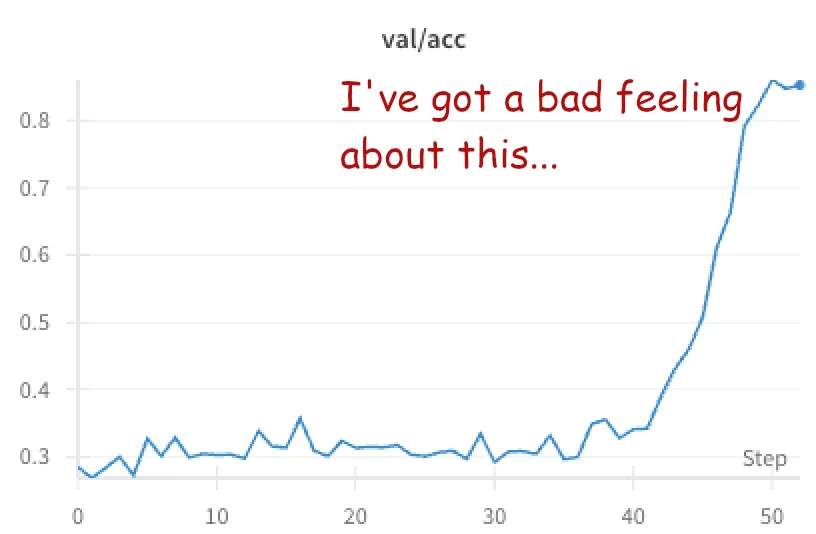
What happened? Once again, we looked to the logs of our agent runs to see. It turns out there was a flaw in the code we had written to validate group correctness. The LLM was able to exploit this flaw by adding all 16 words to each of the 4 groups, leading to a perfect score.
Once we fixed the bug in the reward function, the model’s surprising performance jump disappeared.
Lessons Learned
If you’re building models using reinforcement learning, these lessons may help you deal with reward hacking more effectively:
- Reward hacking is hard to avoid. It happens in nature, in human organizations, in frontier models and in small RL runs. It’ll probably happen to you.
- Record traces to identify reward hacks. You can often spot reward hacking by simply looking at your agent’s traces. Once an agent has learned a hack it will try to apply it often, which actually makes it easier to detect.
- Simple fixes often work. Once you have identified a specific hack, it’s often quite easy to fix it reactively by slightly modifying your reward function to stop incentivizing the hack.
At OpenPipe we love to help customers train models successfully. If you’re interested in applying RL to a problem at your company, please reach out to hello@openpipe.ai to chat!
Join the webinar
If you have questions or want to dig deeper into the above, I’ll be leading a 30-minute webinar “Reward Hacking 101: Keeping Your Agent Honest,” on Mon, Jun 16, 2025 at 10:00 AM Pacific / 5:00 PM UTC. We’ll cover these examples in detail and leave lots of time for Q&A!