RULER: Easy Mode for RL Rewards
July 11, 2025
Reinforcement learning (RL) is highly effective at making agents more reliable, but it’s difficult to implement. One of the hardest challenges when adapting RL to a new task is the need to develop a task-specific reward function, which typically requires either labeled golden data or highly-task-dependent ways of measuring success. These are both difficult to obtain, and make each RL agent training pipeline unique, expensive and error-prone.
RULER (Relative Universal LLM-Elicited Rewards) is a new general-purpose reward function that, when used with GRPO, can reliably improve models with no labeled data, no hand-crafted reward functions, and no human feedback. This dramatically simplifies the process of adapting RL to a new task.
Results
We benchmarked RULER on four realistic agentic applications. Models trained with GRPO+RULER outperform the best prompted frontier model on 4/4 tasks, despite being much smaller and cheaper to run. Surprisingly, we also found the RULER-trained models outperformed models trained with GRPO+hand-crafted reward functions on 3/4 tasks!
| Task | OpenAI o3 | Qwen 2.5* | Qwen 2.5+Manual RL | Qwen 2.5+RULER RL |
|---|---|---|---|---|
| ART-E | 90% | 41% | 96% | 95% |
| Reasoning Classifier | 86% | 60% | 89% | 90% |
| Voice Ordering | 95%† | 73% | 95% | 96% |
| Customer Support Agent | 50% | 62% | 92% | 93% |
How RULER works
We’ve fully open-sourced RULER as part of our agent-training framework, ART. You can find its implementation here, and full documentation on how to use it with training here. If you find it useful, please star the repo to help others find it!
The important steps are:
- ART or another RL framework runs an agent N times for a given set of inputs, each time generating a trajectory (list of inputs and outputs seen by the agent, formatted as OpenAI-style chat completion messages).
- We pass all N trajectories to the RULER reward function.
- RULER deduplicates the trajectory prefixes; for example, if all N trajectories start with an identical system message, it is extracted into a shared prefix.
- RULER passes the shared prefix and N suffixes to a configurable LLM-as-judge, along with a ranking rubric. The judge is asked to give each trajectory a score between 0 and 1, based on whether it successfully achieved its goal according to the rubric.
- The RULER-generated scores are used directly as rewards in a GRPO training step.
- We repeat this process in a loop for M iterations.
For convenience, we also ask the LLM-as-judge to provide a brief explanation of the reasoning behind each score, which is helpful for clustering and fault analysis of poorly-performing trajectories.
Why RULER works
There are two key insights behind RULER that make it more effective than other LLM-as-judge approaches, and even many hand-crafted reward functions.
Insight 1: It is far easier to rank several candidate solutions than to score each of them in isolation. Looking at multiple solutions side by side allows the LLM-as-judge to identify deficiencies and rank them accordingly.
Insight 2: With GRPO, scores do not have to be comparable between different groups, they just need to be comparable within each group. GRPO normalizes scores within each group based on the group’s mean and standard deviation, so the only thing that matters for training are the relative scores within each group. This sidesteps a major issue commonly faced by LLM-as-judges in other contexts, which is that scores for trajectories presented in isolation are often not well calibrated and can’t be compared directly.
Customizing RULER
RULER can be customized by providing a task-specific rubric to the LLM-as-judge. This allows subject-matter experts to tailor its scores to the specific task requirements. However, we have found that this is often not necessary in practice—in fact, it can often lead to worse performance!
Rather than customizing the rubric, better results are often achieved by giving very clear instructions in the system prompt passed to your agent itself. Because RULER has access to that system prompt as part of each trajectory, it can use it to understand the agent’s goals and rank the trajectories accordingly.
A rubric doesn’t have to be complicated. We’ve reproduced the default rubric below in its entirety:
Default Rubric:
- A trajectory that achieves its goal should always get a significantly higher score than a trajectory that does not achieve its goal.
- A trajectory that achieves its goal more efficiently (eg. by avoiding unproductive detours) should get a higher score than a trajectory that achieves its goal less efficiently.
- If one trajectory is only slightly better than another, the difference in scores should be small. If it is significantly better, the difference in scores should be large.
- You may give some partial credit for a trajectory that makes progress towards its goal but does not complete it.
Getting Started
We’ve added RULER to ART, our framework for training and evaluating RL agents. It’s a lightweight framework with few dependencies, and can be installed with pip install openpipe-art. You can find examples of how to use RULER in the ART documentation.
If you find RULER useful, please star the repo to help others find it!
Future work
Thus far, we’ve only tested RULER as a way of scoring trajectories at training time. However, given its flexibility and strong performance, we believe it could also be used at runtime as a form of test-time compute to improve agent performance and reliability.
We also believe that RULER opens the door up to more natural online learning for agents, allowing them to continuously improve performance over time as they’re used. However, this is a topic for future work.
Citation
And if RULER is helpful in your research, feel free to cite:
@online{corbitt2025rulerblog,
title = {RULER: Relative Universal LLM-Elicited Rewards},
author = {Corbitt, Kyle and Gandhi, Saumya and William, Angky and
Jones, Andie and Hilton, Brad and Corbitt, David and
Kovalevski, Bohdan},
year = {2025},
url = {https://openpipe.ai/blog/ruler},
note = {Blog post, OpenPipe.ai}
}Acknowledgements
The research that led to RULER was inspired by the Databricks TAO report, and is conceptually similar. We are unable to directly compare our techniques however because TAO shares little information about their actual scoring process, only the following general outline:
Response Scoring: In this stage, generated responses are systematically evaluated. Scoring methodologies include a variety of strategies, such as reward modeling, preference-based scoring, or task-specific verification utilizing LLM judges or custom rules. This stage ensures each generated response is quantitatively assessed for quality and alignment with criteria.
We also note that the improvements TAO claims are significantly smaller than the ones we see with RULER, so we suspect the approaches are different.
Appendix 1: Task Details
In this section we’ll discuss each of the tasks we’ve tested RULER on to help build intuition on the types of problems it is well-suited for.
ART-E
The ART-E agent is designed to answer natural-language questions by searching an email inbox. We tested several LLM-as-judge models within the RULER harness, as well as several different rubrics and base models. For all runs we used a group size of 4 for a balance between diversity and cost.
Our hand-written reward function, as described in the original blog post, involved comparing generated answers to known-correct golden answers. To train with RULER, we ignored the known-correct golden answers and instead used the RULER rubric to rank the generated answers.
We tried both the default RULER rubric and a custom rubric based on our expert understanding of the ART-E task. Surprisingly the model trained with the default, generic ART-E rubric both converged faster and was slightly stronger!
We tried a variety of judge models including o3, Gemini 2.5 Flash, and Qwen3 32B. For this task we found that all 3 judges were able to produce clear judgements that led to strong results.
| Base Model | Reward Type | RULER Judge | Final Accuracy |
|---|---|---|---|
| Qwen2.5-14B | Hand-Tuned | - | 96% |
| Qwen2.5-14B | RULER | o3 | 95% |
| Qwen2.5-14B | RULER | Gemini 2.5 Flash | 94% |
| Qwen2.5-14B | RULER | Qwen3 32B | 95% |
| Qwen3-14B | RULER | Qwen3 32B | 97% |
Surprisingly, convergence was substantially faster on most RULER runs than with the hand-tuned baseline. We hypothesize that this is because RULER was able to give partial rewards to answers that were close but incomplete. More research is needed here.
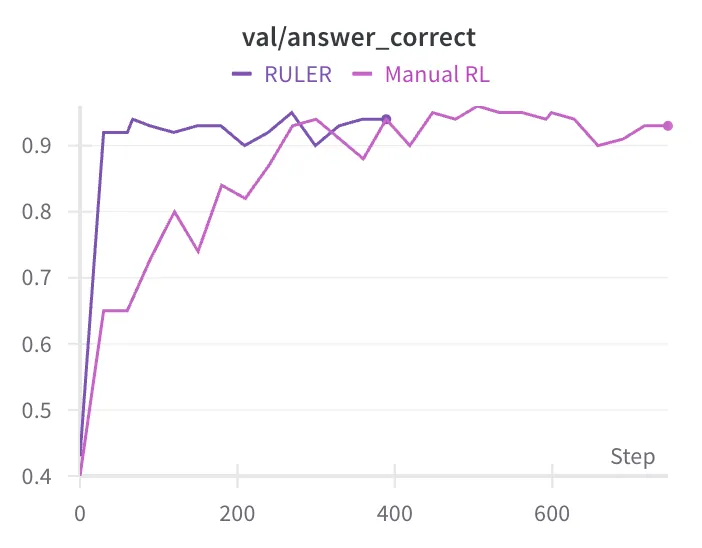
Reasoning Classifier
A customer asked us to develop a tiny domain-specific classification agent suitable for edge deployment. For this small model we used rejection sampling with SFT to warm up the reasoning traces, and then a standard RLVR flow to train a reasoning classifier.
Surprisingly, we found that RULER was able to match and even slightly exceed the performance of the RLVR flow that was based on labeled data provided by the customer, without considering any of the labels at all!
We used Gemini 2.5 Flash as the judge for cost reasons, and 5 rollouts per group.
Voice Ordering
We tested RULER on a voice ordering task we’ve been developing for a large Fortune 500 e-commerce customer. RULER was highly effective, performing comparably to the hand-written reward function based on expert-labeled test cases we had been using previously.
Customer Support Agent
We tested RULER on a customer support agent we’ve been developing for a tier-1 financial services company. RULER significantly outperformed the hand-written reward function we had previously been using based on labeled test cases. Interestingly, it also significantly stablilized training, an effect we’ve seen in other runs as well. We hypothesize this may be because the customer-provided labeled training data actually had some incorrect or noisy outputs. Since RULER ignores labels, these incorrect or noisy outputs didn’t hurt training.
Motivation
Many organizations attempt to deploy AI agents and are frustrated by a lack of reliability, even with the best frontier models. Task-specific RL is a demonstrated way to improve agent reliability, and has been widely adopted by frontier labs. However, adoption outside labs has been slow, in large part due to the difficulty of adapting RL to each new task.
One major challenge in adapting RL to a task is the need for either labeled golden data or high-quality task-specific reward functions. These are both often difficult to obtain, and require significant domain expertise to generate.
Motivated by this challenge, we explored new approaches and eventually discovered a simple but powerful technique that works as an automatic reward function across many diverse tasks, eliminating the need for labeled data or task-specific reward functions.
We hope these improvements will spark a much wider adoption of RL by many organizations building agents today. Towards that end, we’re open sourcing our implementation and results as part of Agent Reinforcement Trainer (ART), our framework for training and evaluating RL agents. If you find RULER useful, please star the repo to help others find it!